Let’s not get overwhelmed at that. Well yes, you could gain some control. With respect to your own website, you could set some rules and limits. That’s a fair play anyway, you are the host after all.
Not every page of your website is alike. Not every page has the same gravity of significance and business potential. Not every link may be followed or allowed to take share of the link juice. There are pages you would want your visitors to visit every day, to those you would want to inhibit a potential view. The preferred parameters a webmaster sets within the website are various.
There are a few tactics to decide how search engines might treat a page or a link on your website. More specifically, to tell the search engine spiders what pages to crawl, index & pass PageRank to.
-
Robots.txt
Probably the most popular and imperative among the web developers and SEOs alike. Robots.txt is a file that is uploaded to the roots of a domain, in which you specify the pages you do not want the search engine bots to crawl. However, the pages may get indexed and accrue PageRank as well.
This is a way of hindering the search engines to rather invest their time crawling on other more important pages on your website than those you deem less or no important. Examples of this could be the Admin control panel pages, images & other miscellaneous ones.
-
NoIndex
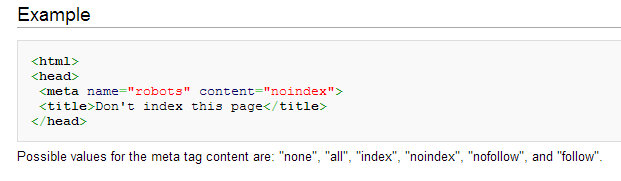
If you do not want certain pages on your website to be indexed, you must use the meta NoIndex tag. These pages can, however, be crawled and accrue PageRank.
An example for this could be a web page with Contact Form that you may not want to get indexed, but want the outbound links on it to be followed, crawled and take share of the link juice.
Meta NoIndex is more superior to Robots.txt in getting selective web pages out of search engine indices.
-
NoFollow
If you do not want certain pages on your website to be indexed, outbound links on it to be followed and pass on the PageRank to, you must use the meta NoFollow tag. These pages can be crawled however.
NoFollow tag is most popularly used by SEOs for PageRank Sculpting. You could also use rel=”nofollow” link tag to inhibit PageRank flow at the link level, so the remaining links without the nofollow link tag stand free of the restriction and allow flow of PageRank. If you would like to set rules at the page level, meta NoFollow tag is to be used.
Appropriate use of the above-mentioned tags on the website help us control the behavior of search engine bots to some extent. The ultimate objective is to help a website meet certain known parameters of doing well in organic searches, and provide the end users with a friendly experience.
Contact us today if you need support in indexing your web pages or controlling the indexed web pages. Your website can be found easily on major search engines like Google, Yahoo, Bing and more with following SEO guidelines. There is no advantage in indexing many of your web pages, but great at giving the targeted set of web pages. It is only by the proper crawl managements that your business web pages relating to your targeted customers gets found on search engine result pages.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation
on the web & mobile strategy that'd suit your needs best.




