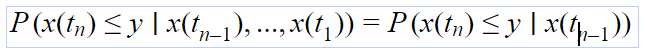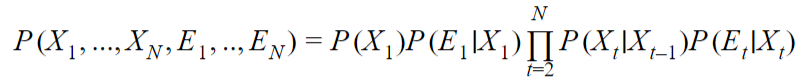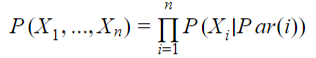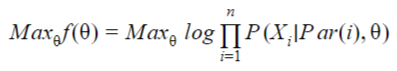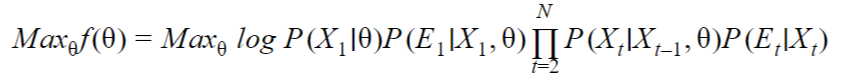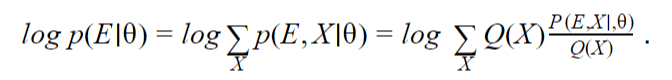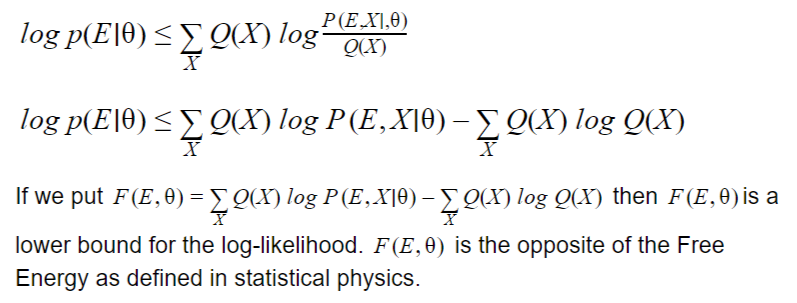In this article we will explore a very special class of classifiers, the Hidden Markov Model Classifiers (HMMs).
They are mainly a statistical and probabilistic model but they have found their entry in the world of Machine Learning since they can be trained and classify data.
A Markov model is a stochastic model designed to model systems which vary over time and change their states and parameters randomly (e.g. dynamical systems) . This can be for example:
The price of a cryptocurrency;
Board games played with one or more dice;
Some values from a stock market;
The trajectory of a vehicle;
Data from the weather of some given location (snow/sunshine/rain).
There are four types of markov models: Markov chains, Markov decision processes, Partially observable Markov decision processes and Hidden Markov models.
Markov models relate to systems – Markov processes – where the future state is only dependent on the ‘most recent’ values.
A stochastic process x(ti), i = 1,2… is said to be a Markov process is for every n>0 and every numerical value y:
In other terms, the value of the state of the system at the instant T = tn only conditionally depends on the value of the state of the system at the previous instant T = tn-1.
This property of the markov model is often referred to by the following axiom:
‘The future depends on past via the present’.
A Markov process with a finite number of possible states (‘finite’ Markov process) can be described by a matrix, the ‘transition matrix’, which entries are conditional probabilities, e.g (P(Xi\Xj)){i,j}.
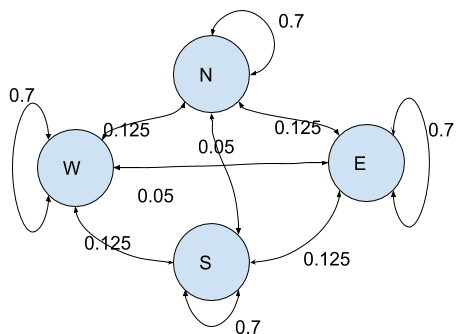
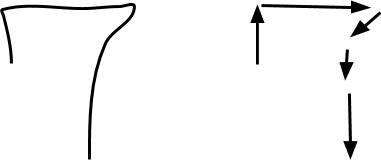
As an example, we consider the markov process created by the movement of an insect. The process has four states: “North, South, East, West” with the following (constant) conditional probabilities:
P(Xi\Xj)
N
S
E
W
N
0.7
0.05
0.125
0.125
S
0.05
0.7
0.125
0.125
E
0.125
0.125
0.7
0.05
W
0.125
0.125
0.05
0.7
A Markov process is usually represented by a graph where the relations between the states are coded by connections.
1. This is often badly understood. This simply means that the future (state) will not depend on anything from the past (states) but only of the present (state).
In our model, at any position, the insect has a higher probability (70%) of keeping up with its trajectory, a small probability (5%) of going back where it came from and equal probabilities or turning left or right (12.5%).
If P is the transition matrix, then the transition matrix from a state at T = tnto a state at T = tn+k is given by the new transition matrix Ǫ = Pk.
The above model is a Markov chain model because it is fully observable. Not all models have such properties, instead often the markov model is hidden from observation and is known to the observer only via side-events.
In this article, we are only interested in the latter, the Hidden Markov models (HMMs). They occur for autonomous systems in which states are partially observable.
In the case of the example with the insect, the hidden model would be the nature of the insect ( cockroaches, ants…) and the observable model would be the directions taken by the insect.
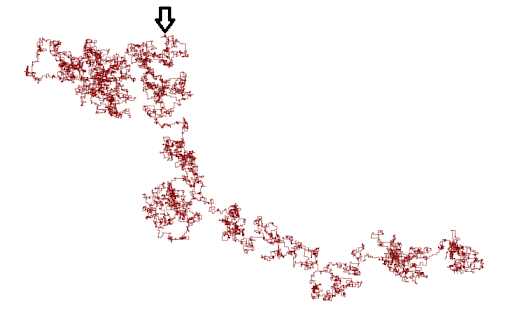
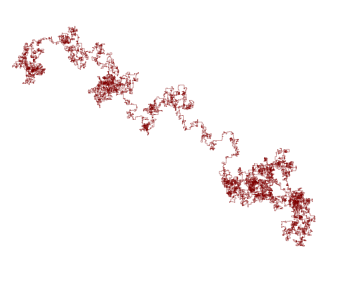
As an example, we display the trajectory of such an insect with 50,000 steps.
A HMM classifier would have to decide the nature of the moving insect (hidden model) from such trajectories (observable model). The program to build such a trajectory is available as a perl script here.
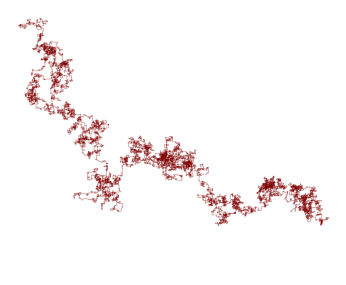
Next we display 4 other samples of such trajectory. An HMM classifier would learn from such a training set as characterizing a given type of insect.
Overview Of Hidden Markov Models
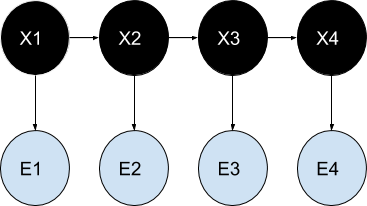
In a hidden Markov model (also named Labelled Markov Chain) , the Markov chain – itself – is hidden (Xi), only we see observable events (Ei) depending on the states of the Markov chain.
Note that in Hidden markov models, variables are discrete and not continuous. The continuous version of HMM is named the linear-Gaussian state-space model, also known as the Kalman filter, not to be considered here.
In terms of classification/recognition this means to be able to classify information given a series of ‘characteristic’ observations. For example, we could classify a moving insect(Xi) knowing only its trajectory(Ei).
Per se, hidden Markov models are not Machine Learning algorithms at all. They are a probability model and bear no information on how to learn, how to be trained and how to classify, so they need in addition algorithms to do so.
Hidden Markov Models are usually seen as a special type of Bayesian networks, the Dynamical Bayesian networks.
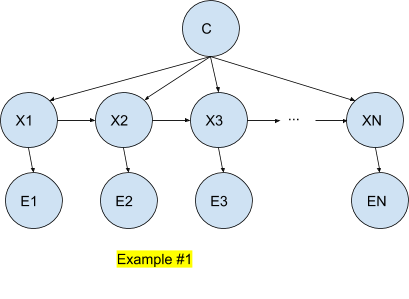
In such a model, the input vectors are N values of the observable model (among n possible states in the finite case) .
The Bayesian network is simplified regards to a general Bayesian network since every node (Xi) has (Xi+1) and C – the category node – as parents.
In the above example, we can express the joint probability as such:
This can be easily checked by following the arcs of the corresponding network.
Same as with the ‘general’ Bayesian network, our goal is to classify the data by maximization of a function, usually the maximal Likelihood, MLE.
This task is simplified since we know the structure of the network and we do not need to have the classifier to ‘learn’ it.
In what follows we explain how to compute the Likelihood in case that the variables are not hidden first and when they are hidden.
MLE Estimation With Non-Hidden Data
Here we recall the principle of MLE – or log MLE – computation (estimation) in the case the variables are not hidden.
To compute the joint probability in a Bayesian network it is in fact quite simple, it is needed to get the products of all the CPDs, eg the product of the conditional probabilities of each Xi regarding to its parents in the network, Par(i).
Therefore the log-MLE can be computed by:
In the case of the Hidden Markov model as described in Example #1, we have the following results:
In a hidden Markov model, the variables (Xi) are not known so it is not possible to find the max-likelihood (or the maximum a-posteriori) that way.
Expectation–Maximization (EM) Algorithm
In the case where the variables are hidden, which is the case here, it is necessary to use a special algorithm to compute the MLE, namely the EM algorithm.
Since log is concave we get:
This is the basic for the expectation–maximization (EM) method which is an iterative algorithm allowing to find the maximum likelihood in such case where the variables X are hidden.
The EM method alternates between an expectation (E) step, which creates a distribution Ǫ for the expectation of the log-likelihood, and a maximization (M) step, which provides the parameters maximizing the log-likelihood found on the E step.
Baum-Welch Algorithm
In the precise case of a Hidden markov model the Baum–Welch algorithm uses the forward-backward algorithm to compute the data in the E-step.
Usage of Hidden Markov Models Classifiers
Hidden Markov Models (HMM) are used for example for :
Speech recognition;
Writing recognition;
Object or face detection;
Fault Diagnostic.
Web page ranking
This allows to treat a handwritten text and a hidden markov model. The same logic applies for speech (time series of succession of phonemes etc…)
ANNEX 1
PERL SCRIPT TO GENERATE INSECT RANDOM WALKS
use strict; #use warnings; my $SVG = “<svg viewBox=\”0 0 2000 2000\” xmlns=\”http://www.w3.org/2000/svg\”>”; #simulate an insect trajectory with markov Model #define the transition matrix my @rows; my @m1=( 0.7, 0.05, 0.125,0.125 ); my @m2=( 0.05,0.7,0.125,0.125 ); my @m3=( 0.125,0.125,0.7,0.05); my @m4=( 0.125,0.125,0.05,0.7 ); #NSEW #my @matrix = ( @m1,@m2,@m3,@m4 ); my $L=”<line x1=\”_X1_\” y1=\”_Y1_\” x2=\”_X2_\” y2=\”_Y2_\” stroke=\”_COLOR_\” />”; #number of iterations of the trajectory my $steps=50000; #initial direction= North my $direction=0; my $color=1; my $X=400; my $Y=400; my $iter=1; for(my $i=0;$i<$steps;$i++) { my $r=rand(100); my $p=0; if($direction>3) { die(“algorithm error\n”); } if($r<5) { #5% chance this happens $p=0.05; } elsif ($r<75) { #70% chance this happens $p=0.7; } else { #2×12.5% chance it happens $p=0.125; } #print “go to $p \n”; if($direction ==0) { @rows=@m1; } elsif($direction ==1) { @rows=@m2; } elsif($direction ==2) { @rows=@m3; } elsif($direction ==3) { @rows=@m4; } else { die(“algorithm error\n”); }
for (my $a=0;$a<4;$a++) { #print “row=$rows[$a] \n”; if($rows[$a]==$p) { $direction=$a;
if($color==1) { $L2 =~ s/_COLOR_/black/; $color=0; } else { $L2 =~ s/_COLOR_/red/; $color=1; } #add it to the svg $SVG=$SVG.”\n”.$L2; } $SVG=$SVG.”</svg>\n”; print $SVG;
Acodez is a renowned web development company in India offering Emerging Technology Services to our clients across the globe. We also offer all kinds of web design and web development services to our clients using the latest technologies. We are also a leading digital marketing company providing SEO, SMM, SEM, Inbound marketing services, etc at affordable prices. For further information, please contact us.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation on the web & mobile strategy that'd suit your needs best.
Rithesh Raghavan, Co-Founder, and Director at Acodez IT Solutions, who has a rich experience of 16+ years in IT & Digital Marketing. Between his busy schedule, whenever he finds the time he writes up his thoughts on the latest trends and developments in the world of IT and software development. All thanks to his master brain behind the gleaming success of Acodez.