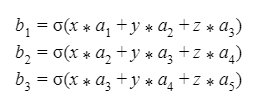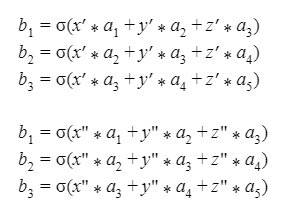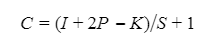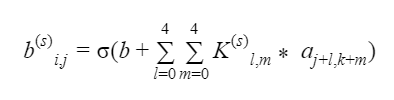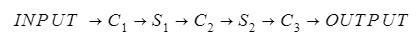The LeNet architecture came historically as an attempt to classify 2D images and to produce a simple convolutional network that could be more efficient than ‘small’ neural networks, which ones have difficulties learning training sets, and then large neural networks which contain too many parameters to be conveniently exploited.
It is possible to design very specific neural network architectures which are dedicated to recognizing 2D maps, while these networks are eliminating noise, distortions, and fluctuations inside the input data.
Such specific networks are convolutional networks. Convolutional networks can be designed to exploit ‘local’ patterns and combine the results into a whole. This is the idea of the LeNet architecture.
The LeNet architecture was introduced around 20 years ago by Yann LeCun and other researchers and an initial description of the network design can be found in [1].
LeNet-1 ( and other following LeNet & CNN architectures ) are based on two main ideas acting as the pillars of such models:
Building a set A of local area A in the 2D map unique common weights, which can be called units. The output of A is the feature maps, e.g 2D maps which are outputted from areas with a common weight;
Cascading’ local convolutional feature maps applied to several hidden layers.
We shall detail these designs specificities:
Feature map System
A feature map is created by applying a convolution operation to the initial matrix.
Eg: feature Map = input matrix * kernel matrix
where ‘*’ is the convolution operator. This means that, in fact, only a few weights will be used, the ones inside the kernel matrix.
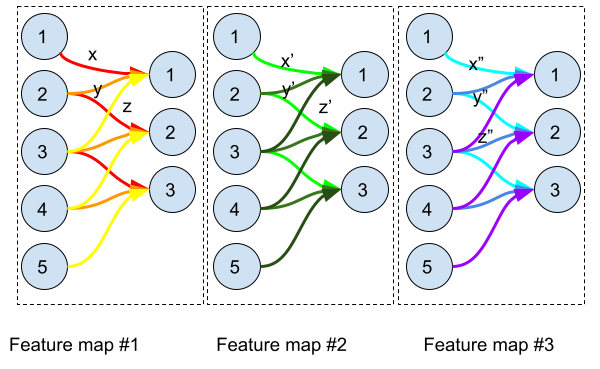
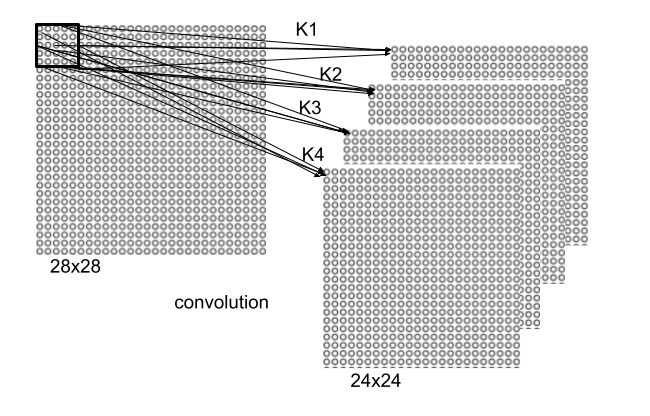
In the above illustration, we demonstrate the concept of a common group of weights. A feature map is created by convolution of a plan with a kernel/filter. The feature map #1 is created by the kernel (x,y,z) in the following way:
Where are the (five first) neurons of the N hidden layer, the (three first) neurons of its successor, the (N+1) hidden layer and is an activation function.
All the same, the feature maps #2 and #3 are created respectively by the kernels (x’,y’,z’) and (x”,y”,z”).
The reasons for considering local connectivity comes from the fact that it may seem inordinate to use networks with fully connected layers in order to classify 2D maps (‘images’). Indeed, such a network architecture does not fully address the spatial nature of the data.
A fully connected network would consider all the same input pixels which are close to each other or to the contrary who are far from each other.
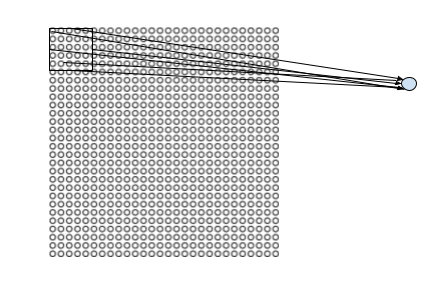
So LeNet-1 (and in fact any typical CNN) does not connect every input pixel to every hidden neuron. Connections are done only in a small localized region of the image.
Such localized regions are defined by a Local receptive field, a submatrix of relatively small dimensions, which is in fact the convolution kernel.
LeNet-1 Detailed Design
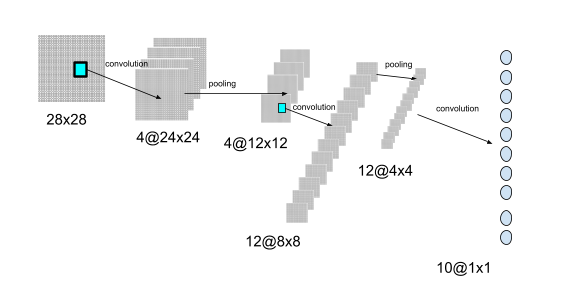
LeNet-1 applies originally to 16×16 pixels maps which are extended to 28×28 pixels maps by adding a 6 pixels blank frame around the original map to avoid edge effects in the convolution computations.
In the original leNet-1 architecture, the input is therefore a 28×28 pixel image data. This represents 784 input neurons (+ the bias neuron). It doesn’t matter how they are ordered.
We assume here that they are ordered by lexicographical order on the pixels coordinates , eg if .
The whole set of possible values of the input is already huge, eg it is which means that it is impossible to consider an exhaustive list of all the values.
Over that initial plan, 4 regions – aka feature maps – from four 5×5 kernels will be created.
The first layer (the input isn’t considered to be a layer) will therefore have 4 feature maps of size 24×24 each, which makes 4x24x24=2304 neurons (+1 bias neuron)
We represent here the input neurons ordered as a matrix:
Over that initial input matrix, 4 filters of size 5×5 ( e.g 25 weights each ) are applied by convolution so that they generate 4 feature maps of size each 24×24.
The size C of a convoluted feature map is given by the formula:
Where I is the size of the input matrix, P the margin, K the size of the kernel, and S the stride.
Here
The values of the first layer are given by the convolution formula:
Where is the (i,j)^th neuron, lexicographically counted, of the s-th feature map, is the (l,m)^th neuron, lexicographically counted, of the s-th 5×5 filter and is the (j+l,k+m)^th neuron, lexicographically counted of the input and b is the bias neuron. is an activation function, usually the sigmoid.
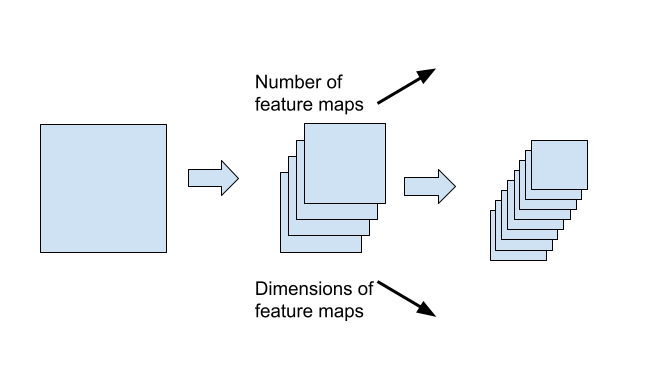
The design consists of refining more and more possible patterns into a bigger set of feature maps which are in turn of smaller and smaller sizes.
LetNet-1 has an overall of 3 convolutional layers , and 2 pooler (sub-samplers) layers . The network can be described by the following flow:
Once the input has been convoluted into 4 feature maps, each feature map is pooled into 4 corresponding feature maps of dimensions 12×12 each.
The pooling is done over sub-matrices of dimension 2×2 so that it divides the amount of neurons by 2*2, e.g. 576 neurons + the bias neuron.
In the next layer, convolution is done again this time with 3 filters of dimensions 5×5 each. Since the convolution is done on each of the 4 pooled feature maps, this multiplies the amount of feature maps to 4*3=12 but the dimensions of each new feature map are reduced from 12 to C’=(12-5)/1+1=8.
This creates 768 neurons (+ bias). This new layer is pooled again so the size is reduced to 192 neurons (+ bias). Finally, we perform a final convolution of the 12 ‘tiny’ 4×4 feature maps to create 10 neurons.
LeNet-1 originally classifies handwritten digits from 0 to 9 but the ten categories can be anything else.
The LeNet-1 architecture, which is quite ancient in terms of neural networks, is inspired by the way the brain processes optical information. The series of convolutions and pooling process an image so as to extract more and more adequate features.
The final weights given to these features will determine the classification of the data into one of the possible categories.
LeNet-1 can work very well with any sort of imagery, e.g. 2D diagrams because the color codes and the patterns can be treated as image recognition, e.g. with the same technique used for recognizing a handwritten digit.
Of course, LeNet-1 has improved since the time but in the present article, we wished to go into the details of a typical convolution network.
Acodez is a leading web development company in India offering Emerging Technology Services to our clients across the globe. As a web design company, we offer all web development services too to our clients using the latest technologies. We also have a dedicated digital marketing division wherein we provide SEO, SMM, SEM, Inbound marketing services, etc at affordable prices. For further information, please contact us.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation on the web & mobile strategy that'd suit your needs best.
Rithesh Raghavan, Co-Founder, and Director at Acodez IT Solutions, who has a rich experience of 16+ years in IT & Digital Marketing. Between his busy schedule, whenever he finds the time he writes up his thoughts on the latest trends and developments in the world of IT and software development. All thanks to his master brain behind the gleaming success of Acodez.