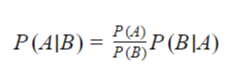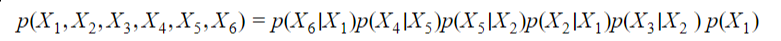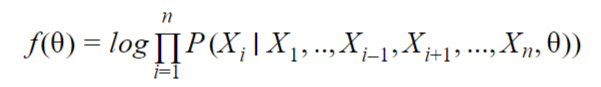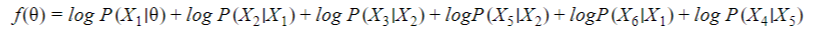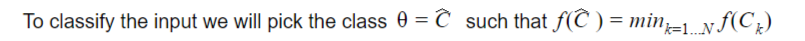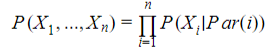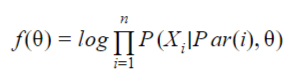Bayesian networks are based on bayesian logic. In Bayesian logic, information is known using conditional probabilities which can be computed using Bayes theorem.
Note that Bayesian Neural Networks are a different concept than Bayesian network classifiers, even if there is some common ground between the two.
Bayes Theorem
Bayes Theorem states that if A and B are two events which can be realized or not , then we have:
The term ‘A|B” means that A is realized knowing priorly that B is realized.
We refer to that article for an introduction to the basic properties of Bayesian logic.
The Bayes theorem can be reformulated as:
posterior (A|B)=prior(A) x support from additional facts (B|A/B)
Which can be rewritten as :
posterior = prior x likelihood / evidence.
Here we defined the likelihood term as p(B|A) and the evidence term as p(B).
Principles Of Bayesian Networks Classifiers
Bayesian Networks are classifiers which are a generalization of the naive Bayesian Classifiers described there.
Historically Bayesian Networks (BNs) were not considered as classifiers ( and hence could not be considered into the Machine learning category ) but since naive Bayes classifiers obtained surprisingly good results in classification, BNs became increasingly used as classifiers.
Bayesian networks do not suppose that the input parameters of a bayesian classifier are independent from each other. Therefore the bayesian system form a directed graph (network) where variables are linked between each others by conditional probabilities as well.
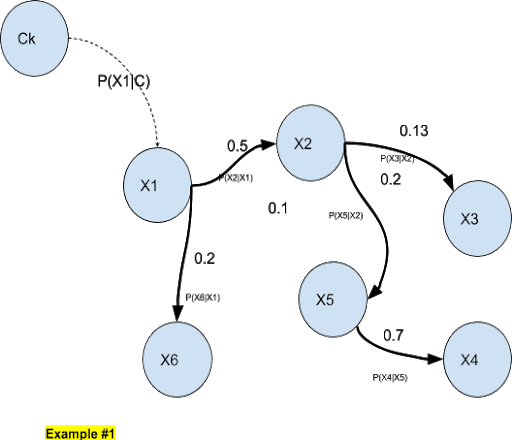
We recall that a bayesian classifier takes n input parameters which forms an input vector characterizing an object X to classify among N candidates classes {C1,…, CN} . For example X = (X1,…,Xn).
A naive bayesian classifier achieves its goal by computing products known as Maximum Likelihood (MLE) or maximum a Posteriori (MAP) which involves the knowledge of P(Ck) k=1,…,N and P(Xi|Ck) i = 1,..,n.
A bayesian network will require more complex computations involving the cross-probabilities P(Xi\Xj) (i,j) = 1,…,n. To visualize this, we draw the n variables and we connect them when they have a dependency relationship (eg they are not independent variables from each others )
In the above example, we have a 6-dimensional input vector where variables are dependent on each other.
The Bayesian networks are of course a more accurate model than the naive Bayesian classifiers but they require to be able to compute Maximum Likelihood (or similar products) , which may be a problem because of the cross-terms. Note that Bayesian networks also generalizes Hidden markov models classifiers.
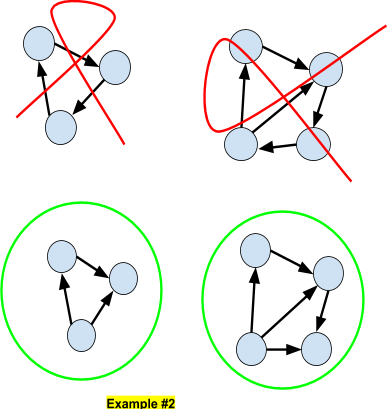
DAG
Bayesian Networks are Directed Acyclic Graphs (DAG) in the sense that it is impossible to connect two nodes by a path. Here we show some examples of non-DAG (top) and DAG (bottom) networks.
d-separated/d-connected
If A and B are two nodes in the graph and A and B cannot be connected by a directed arc, then A and B are said to be d-separated, otherwise they are said to be d-connected.
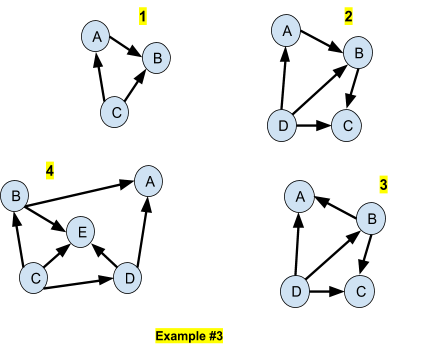
In the above 4 networks (Example #3), we have the following properties:
A,B and C are all d-connected between each others
A,B,C and D are all d-connected between each others
A and C are d-separated
A and E are d-separated
Joint Distribution Model
Example
A Bayesian network always represents a joint distribution. In the above example (Example #1) with the 6-dimensional input vector, we have:
The log-MLE here is:
And we look for a minimum of ƒ over the classes to perform the classification.
In our example, the log-MLE will be:
In the example, the class node is only connected to X1so that the maximization of ƒ consists only in the maximization of P(X1|θ).
General Case
To compute the joint probability it is in fact quite simple, it is needed to get the products of all the CPDs, eg the product of the conditional probabilities of each Xi regarding to its parents in the network, Par(i).
We compute the joint probabilities in the 4 networks of Example #3:
The likelihood will be computed identically. Let us assume that there is a ‘universal’ node which connects to all the nodes of the network and which represent the category node.
The log-likelihood will be:
Therefore the classification of a sample (X1,..,Xn) will be done by picking up the category (or a category if there are several possible candidates) which maximizes the likelihood.
The CPDs will be estimated by the samples of the training set. We give the value of the log-likelihood with the 4 networks of Example #3:
The problem consists in describing – and computing – the cross conditional probabilities, e.g. the probability distribution of X conditional from X’s parents, from the training data.
The Bayesian distributions can be estimated from the training data by maximum entropy, for example but this is not possible when the network isn’t known in advance and has to be built.
In fact the complex problem here is to define the graph of the network itself which is often too complex for humans to describe it. This is the additional task of Machine Learning, besides the classification, to learn the graph structure.
Learning The Graph Structure
Here are the main algorithms used for learning the Bayesian Network graph structure from training data:
Rebane and Pearl’s recovery algorithm;
MDL Scoring function;
K2;
Hill Climber;
Simulated Annealing;
Taboo Search;
Gradient Descent;
Integer programming;
CBL;
Chow–Liu tree algorithm.
Overview Of Different Bayesian Networks
The main techniques of building specific classes of bayesians networks are based on selecting feature subset or relaxing independence assumptions.
Besides this, there are improvements of the naive Bayesian networks such as the AODE classifier which are not themselves Bayesian networks, which is outside the scope of the present article.
Tree Augmented Naive-Bayes (TAN)
The TAN procedure consists in using a modified Chow–Liu tree algorithm over the nodes Xi, i=1,..,n and the training set, then connecting the Class node to all the nodes Xi, i=1,..,n.
BN Augmented Naive-Bayes (BAN)
The TAN procedure consists in using a modified CBL algorithm over the nodes Xi, i=1,..,n and the training set, then connecting the Class node to all the nodes Xi, i=1,..,n.
Semi-Naive Bayesian Classifiers (SNBC)
SNBC is based on relaxing independence assumptions.
2 Note that using MDL – aka minimal description length score – (or any other ‘generic’ scoring functions) in order to learning general Bayesian networks usually result in poor classifiers
1Chow and Liu algorithm finds the optimal (in terms of log likelihood minima ) bayesian network.
Bayesian Chain Classifiers (BCC)
This is a special case of chain classifier applied to Bayesian networks. They are useful for multi-label classification, e.g. when classification may be multiple.
Hidden Markov Model Classifiers (HMMC)
These are discrete Dynamical bayesian networks classifiers, They are described in more detail here.
An overview of the performances of Bayesian Networks
Bayesian networks have been introduced into a wide variety of usage, medical diagnostic, for example or helping to intrusion detection techniques. As mentioned MDL constructed networks behave generally badly while TAN networks perform satisfactorily.
We only gave a very basic overview of the topic. Bayesian networks as classifiers are quite new and their performances still debatable and paradoxically they may even behave inferiorly to a naive bayesian network.
Acodez is a renowned website development and Emerging Technology Services company in India. We offer all kinds of web design and web development services to our clients using the latest technologies. We are also a leading digital marketing company providing SEO, SMM, SEM, Inbound marketing services, etc at affordable prices. For further information, please contact us.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation on the web & mobile strategy that'd suit your needs best.
Rithesh Raghavan, Co-Founder, and Director at Acodez IT Solutions, who has a rich experience of 16+ years in IT & Digital Marketing. Between his busy schedule, whenever he finds the time he writes up his thoughts on the latest trends and developments in the world of IT and software development. All thanks to his master brain behind the gleaming success of Acodez.