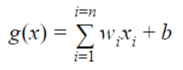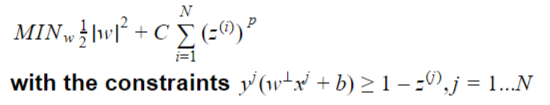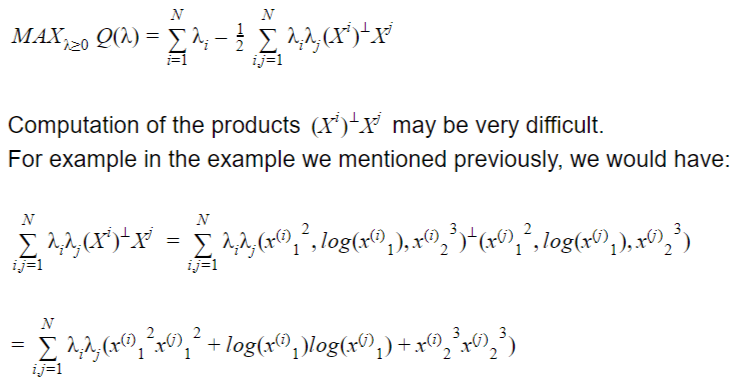In the present article, we shall explain what are the Support Vector Machines (SVMs) and how the kernel-based SVM classifiers are working.
Support Vector Machines operates as classifiers using several properties of linear algebra. They can separate a dataset into higher-dimensional spaces using kernel methods.
They require some understanding of basic functional analysis and linear algebra and so their theoretical background have not always made them the choice for concrete classificator implementations. This said, they often achieve similar or even better results than the equivalent neural networks classifiers or the probability-based classifiers.
Some Quick Facts About SVMs
SVMs are a special class of Machine learning models named “nonparametric” models. “Nonparametric” means that the parameters only (and directly) depends on the training set.
The only information given to a SVM in a supervised training is to learn from a set of couples (xi,Ci) where xi is a n-dimensional vector and Ci is a class label, among k possible classes labels.
SVMs will seek to build decisions functions to classify the data. For this, they will only rely on a special set of data , from the training set, namely the support vectors. This means that an important amount of the training data won’t be used at all.
SVMs belong to a family of generalized linear classifiers and they can be seen as an extension of the perceptron.
Some Linear Background
SVMs are using decision functions to separate several sets of data.
In the simplest case, linear binary classification, we consider a set A which must be separated into two subsets B and C.
The set A is here a set of vectors x=(x1,…,xn) in a n-dimensional space.
Finding a function g is of course always possible since it is enough to define it over the sets B and C .Of course we look for special, generic, type of functions.
The most simple function is a linear function:
It is not always possible to find such a function g. If it is possible B and C are said to be linearly separable.
From this it is possible to achieve multi-class seperation. There are several ways to define multi-class separation, it can be achieved by ‘all-in’one’, binary tree or pairwise separation, for instance.
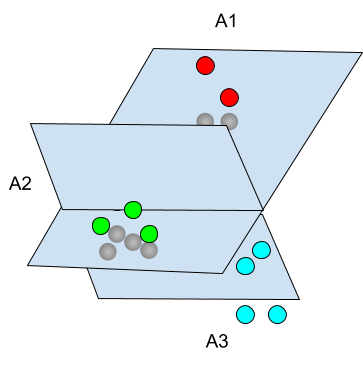
Geometrically speaking, this can be easily visualized as the building of geographical areas from hyperplanes. In the example above, we seperated 3 areas A1,A2,A3 by using 2 functions g1,g2 such that the signs of both g1(x) and g2(x) decide if x belongs to A1, A2 or A3.
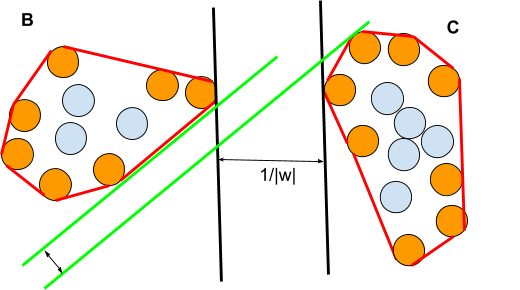
Hard Margin Concept
The hard Margin M is defined for two linearly separable sets B and C.
The separating hyperplane -defined by g(x)=0 – is in the middle.
That optimization problem is the hard-margin problem for the support vector machines.
The motivation for maximization of the margin is because it will provide the most ‘generic’ classification when considering further samples, not from the training set.
Definition Of Support Vector
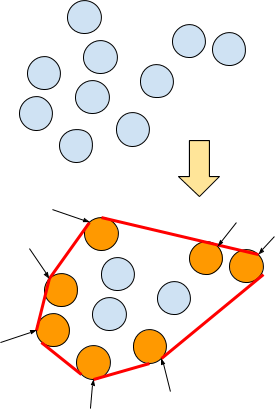
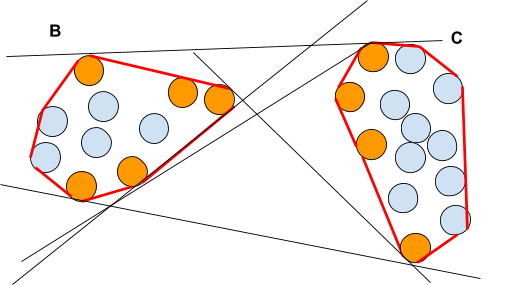
To visualize it, one must introduce the notion of support vectors. These are the vector belonging to the border of the convex hull of each set. (I)
A convex hull is the smallest convex set containing a given set.
In the above picture we pictured the convex hull in red and the support vectors in orange. There are 7 support vectors among the 10 vectors. Only these support vectors will be used for the computation of the separating hyperplane.
Note that it is also possible to transform B or C via a translation and /or rotation (affine transformation) for instance, eg to apply a linear transformation defined by a unit matrix Z such that C’ = ZC. Still only the support vectors – as we defined them – will be to consider.
Some definition(II) of support vectors may differ, eg only including a subset of the border of the convex hull consisting of all the vectors having contact points with at least one separating hyperplane (see fig below).
In such definition (II) the support vectors are defined for pair of sets.
Optimization Problem (Linear Case)
In case the set are linearly separable, we have to solve the following optimization problem:
This problem is not very hard to solve.
We can use a classical Lagrangian optimization technique. Here we will consider the (dual) equivalent optimization problem:
Such SVMs are named the Hard-Margin SVMs.
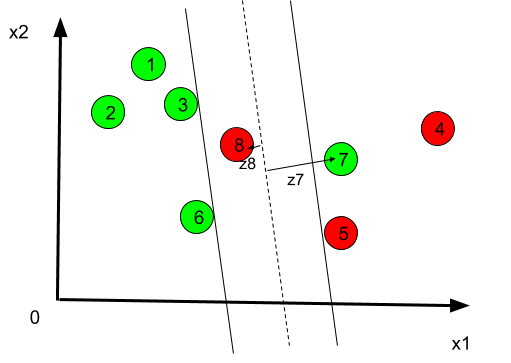
Soft Margin
If the data are not linearly separable, e.g the convex hulls of the sets to seperate are not disjoint, then another technique must be seeked, this is named the soft-margin technique.
If a slack variable is <1 , then the corresponding data is still correctly classified (even if the margin is not optimal in such case) (case I)
If a slack variable is >1 then the corresponding data is not correctly classified (case II).
We need therefore to find the optimal hyperplane with the minimal amount with slack variables are minimal. For this we introduce a very important parameter, named the C-parameter and we have the soft-margin optimization problem:
The solution of this problem are the soft-margin hyperplanes.
The value of p are typically chosen to be 1 or 2 and depending on the choice, the soft-margin hyperplane is called respectively L-1 or L-2 hyperplane.
The resolution of the optimization problem is essentially the same as with the hard-margin, using Lagrangian multiplicators.
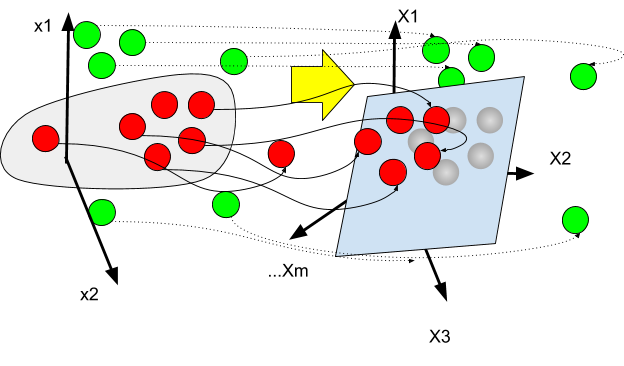
Mapping To Higher-Dimensional Space
The soft-Margin SVM may not always be suitable because it includes some mis-classified points (‘noise’) and one may want to look for a classification method without such problems.
The original finite-dimensional space is mapped into a higher-dimensional space – the ‘feature’ space- , with the goal to make the separation easier in that space.
In the above illustration, we represent the mapping from the initial space to the feature space.
In such cases we revert to the hard-margin scenario.
The Optimization problem is :
Kernel-Based SVMs
We seek therefore to find a symmetric function H : (x,y) → H(x,y)named a kernel and such that H(xi,xj )= XiXj
Introducing the kernel mean there is no need to process the (often complicated) feature space directly (Kernel’s trick).
In such a case the optimization problem can be solved because if the kernel is a semidefinite positive function as well, we need to solve a concave quadratic programming problem.
Kernel-based SVMS are a special part of the Kernel classifiers and should be explained in another article.
SVMs to the difference of other classifiers such as the Neural Networks need a slightly more important theoretical background. They are not always simple to use in the general case.
Acodez is a renowned website development and Emerging Technology Services company in India. We are also a leading web application development company in India wherein we develop custom applications using the latest technologies. We are also a leading digital marketing company providing SEO, SMM, SEM, Inbound marketing services, etc at affordable prices. For further information, please contact us.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation on the web & mobile strategy that'd suit your needs best.
Rithesh Raghavan, Co-Founder, and Director at Acodez IT Solutions, who has a rich experience of 16+ years in IT & Digital Marketing. Between his busy schedule, whenever he finds the time he writes up his thoughts on the latest trends and developments in the world of IT and software development. All thanks to his master brain behind the gleaming success of Acodez.