The perceptron is an algorithm used for classifiers, especially Artificial Neural Networks (ANN) classifiers.
In layman’s terms, a perceptron is a type of linear classifier. It makes a prediction regarding the appartenance of an input to a given class (or category) using a linear predictor function equipped with a set of weights.
The perceptron was originally a machine built in the 60’s, not exactly an algorithm (hence the name). The name “perceptron” has been historically used in recognition of the pioneering work of Frank Rosenblatt.
The root idea for the perceptron concept is parallel computing. In such a context, inspired by biological neural nets, parallel computing is a set of n independent computations ,φ1,…,φn , taking an identical input X (a feature vector) and then merged into a multi-vector function Ω which is itself transformed into the end-function Ψ(X).
The n independent functions “transmits” their computational results to Ω which decides what will be the end value of Ψ(X).
The value of Ψ(X) will be usually boolean with outputs values of 0 or 1, meaning that Ψ is a predicate.
In other terms, Ψ will “predict” something about X. For example, “X is a square” (if X is a 2D geometric figure) , “X is an apple” (if X is a fruit). Or “X is a tailor” (if X is a person with a profession).
The perceptron is a way to “merge” the n parallel computations to get the predicate by means of linear calculus. The perceptron will simply get a weighted “voting” of the n computations to decide the boolean output of Ψ(X), in other terms it is a weighted linear mean. The perceptron defines a ceiling which provides the computation of (X)as such:
Ψ(X) = 1 if and only if Σamaφa(X) > θ
There are many sides from which the perceptron design can be viewed.
The step function can be considered as a decision function or as an activation function, similar to the way a neuron works.
The perceptron is in fact an artificial neuron using the Heaviside function ( e.g. the ceiling computation ) as a step function.
Analogy Between A Perceptron And A Neuron
The perceptron was created as a virtual neuron by considering the way human intelligence works. It does suggest how a brain might be organized, but cannot at all explain how any living brain is in fact organized.
Even if artificial neurons and perceptrons have been created from the progress in neurosciences which started in the 50’s, they are quite different from their biological counterparts in many ways.
Our modern planes have been inspired by birds while horses inspired the designs of modern cars but these transportation systems share in fact very few common points with the aforementioned animals. Therefore artificial neurons ebem if they are inspired by real neurons are in fact quite different and far less complex than their biological counterparts.
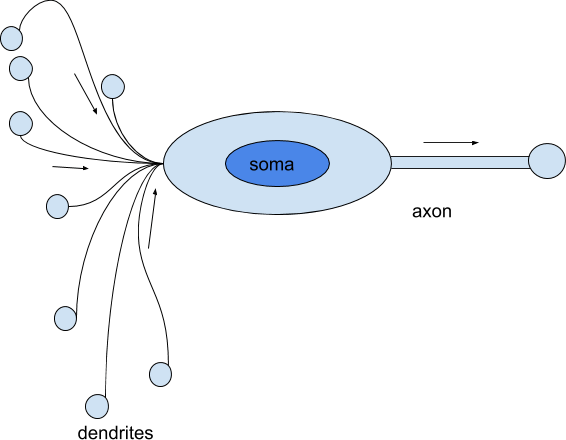
A biological neuron receives signal through others neurons via the dendrites. The dendrites can receive a large amount of signals from the neighboring neurons and they can weight these signals using a chemical process involving the synaptic neurotransmitters.
Negative multiplication is possible by using oppositely charged ions. In a real neuron, the dendrites acts as the input vector X.
Inside the biological neuron itself, the soma, which is a bulbous, non-process part of the neuron, acts as the summation function of all the inputs and transmits an all-in signal to other neurons via an axon.
Geometrical Interpretation Of The Perceptron
Historically the perceptron was developed to be primarily used for shape recognition and shape classifications. For example, deciding whether a 2D shape is convex or not.
The activation function (or transfer function) has a straightforward geometrical meaning. If the data to classify are represented in a multi-dimensional space of dimension n, for example using a vector X with coordinates (X1,…,Xn), then the transfer function creates a hyperplane H which separates the space into two parts: the part where the data are classified as 1) belonging to the class and 2) not belonging to the class.
For instance, as a practical example, we consider the space of the fruits and among them we wish to classify which ones are watermelons .
There are many ways that fruits could be represented in a n-dimensional space. For example, the price they cost, their life duration, their colors etc…
Here we will simply identify them by their weight (X1) and their price(X2) .
Here we wish to classify which inputs are watermelons and which are not. Our transfer function implies the creation of a line of equation m1X1 + m2X2= θ which separates the 2D space into an area where watermelons are expected and an area where they are not expected. Watermelons have important weight and small price, the separation creates therefore an adequate region for them as displayed in the above picture.
Note that in general, the separating hyperplane will be of dimension superior to 1 or even 2. For instance the space X can have 500 dimensions. Then the hyperplane is a subspace of dimension 499.
Training
Without training, there is no real interest in the perceptron as we described it. We must therefore dispose of an initial training set D. The perceptron needs supervised learning so the training set will consist of objects from the space X labelled as belonging or not to the binary class or category we look into.
For example, our training set may consist of 100 fruits represented by their prices and weights and labelled as ‘watermelons” or “not watermelons”. The perceptron will initially iterate through that learning set before becoming operational.
If that learning set is not linearly separable then the perceptron (at least the ‘classical’ perceptron) will not be properly trained and will fail to operate.
A learning set which is not linearly separable means that if we consider the p samples in the training set D, then if A is the set of the fruits which are watermelons and A’ the set of the fruits which are not watermelons, then it is not possible to find a hyperplane H which separates the space with A being on one part and A’ on the other part.
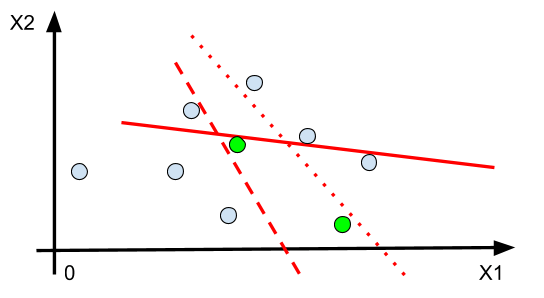
For example, the previous figure shows a situation where the watermelons (green dots) are not linearly separable from the other fruits (blue dots). In other terms, any separating line (in red) will always separate the space in such a way that there will be blue dots on both sides.
In the normal situation where the training set D is linearly separable, we must describe how the training algorithm for the perceptron works.
We define the training set D as such:
D is made of s input vectors: X(1),…,X(s) together with s outputs.
The s outputs are boolean, they indicate if the input vector from the training set belongs to a given category or not (recall that the perceptron is a binary classifier)
The goal of the training is to compute the weights mi and the bias (ceiling) θ. We can represent the hyperplane separating the two regions of the space as:
W.X = 0
With W = (-θ,m1,…,mn)and X = (1,X1,…,Xn)
At the start of the training, we initialize our weights with a null value (or a ‘small’ value).
The s input vectors will be described as such:
X(1)=(1,X(1)1,…,X(1)n)
…
X(s)=(1,X(s)1,…,X(s)n)
During the training, the weights will evolve and will be readjusted. The weight will change using a learning rate r which will be a positive coefficient less than 1.
Step 1: The product W.X(j) is computed and we define yj = 1 if the product is strictly positive and 0 otherwise.
Step 2: The weights are updated using the formula:
mi(new) = mi(old) + r(dj – yj)Xi(j)
For i = 0,1 … n
The steps are iterated until all the samples of the training set are correctly classified.
As we explained the training is possible only if the two sets ( the ones belonging to the category and the ones not belonging to that category ) are linearly separable. This will happen, for example, if the convex hull of these two sets are disjoint.
The perceptron convergence theorem guarantees that the training will be successful after a finite amount of steps if the two sets are linearly separable.
The mathematics involved with such concepts may imply basic functional analysis theory, convex analysis and famous theorems such as the Hahn-Banach theorems but this is outside of the scope of the present article.
Geometrically speaking, the hyperplane of equation W.X=0 will seek the best position to separate the two areas of the learning set.
To illustrate concretely this, we will use a small learning set with fruits and consider once again the category of fruits which are watermelons.
X1 (weight g)
X2 (price $)
d_j (is a watermelon?)
10
12
0
100
23
0
105
5
1
10
5
0
80
10
0
110
7
1
The following program in C# will train the perceptron:
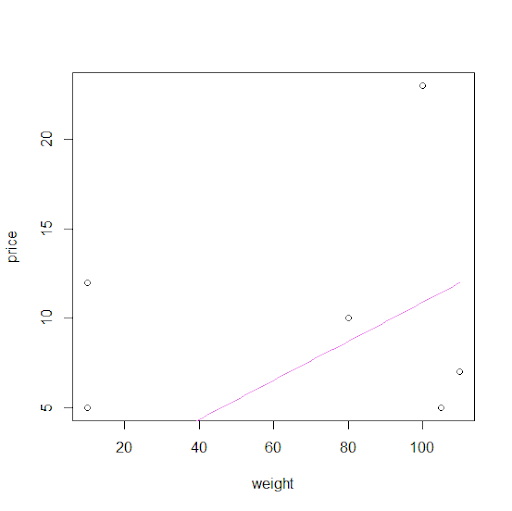
We represent graphically the results. The line (hyperplane) separates the watermelons (at the bottom ) from the others fruits.
As we can see there are many other possible hyperplanes. It doesn’t matter since we look for a classification that works and so all working hyperplanes are equivalents here.
Here we talked about single-layer perceptrons without backpropagation.
The XOR Controversy
The XOR problems consists in using the Perceptron (and ANNs in general) so to classify data generated from XOR operation, namely 4 values:
X1
X2
d_j
0
1
1
1
0
1
1
1
0
0
0
0
The perceptron – which ages from the 60’s – is unable to classify XOR data. The reason is that XOR data are not linearly separable. This can be easily checked. A controversy existed historically on that topic for some times when the perceptron was been developed.
The perceptron is able, though, to classify AND data.
The Various Types Of Perceptron
There are other types of perceptron and some of them have the ability to classify non-linearly separable data
Pocket algorithm
This is a variant of the perceptron which keeps the result of all previously seen computations and will return the best one it keeps “in the pocket” rather than the actual one which has been computed, if it is not optimal
Maxover algorithm
This is an algorithm which will look to train with a pattern of maximum stability, finding the largest separating margin between the classes. It is robust and does not need data to be linearly separable.
Voted Perceptron
This is a simple algorithm which creates new perceptrons all the time a classification fails and ends by voting which one is the best.
-Perceptron
Uses a pre-processing layer of fixed random weights, with thresholded output units
Acodez is a renowned Emerging Technology Services company. We also a leading website design company in India offering services to our clients using the latest technologies. We are also a leading digital marketing company providing SEO, SMM, SEM, Inbound marketing services, etc at affordable prices. For further information, please contact us.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation on the web & mobile strategy that'd suit your needs best.
Rithesh Raghavan, Co-Founder, and Director at Acodez IT Solutions, who has a rich experience of 16+ years in IT & Digital Marketing. Between his busy schedule, whenever he finds the time he writes up his thoughts on the latest trends and developments in the world of IT and software development. All thanks to his master brain behind the gleaming success of Acodez.