The role of data scientists is very interesting. They are often open to new challenges and are exploring newer opportunities. Also, they are looking out for new tools that will help them soar greater heights and give them solutions to a lot of their questions. So once a tool comes into place, it is required that they be proficient in everything about the tool, regardless of the number of tools that are introduced every time.
They are required to have a clear understanding and syntax of the statistical programming languages, which will help them to develop data processing systems, databases, and data visualization tools. It is not necessary that all data scientists be programmers or need to have studied programming. However, it is important that they have clear and precise programming knowledge. It is required that they have a clear understanding of the tools that are necessary for the programming to work, along with a user-friendly graphical interface, using which the data scientists can create predictive models with their awareness or understanding of programming.
Data scientists’ have a lot to plan, learn and understand; so during this time, it would not be an easy task for them to search for a tool that helps in with predictive programming each time it is necessary. Hence, we decided to provide a little insight into the tools that can be used for data visualization, statistical programming languages, algorithms, and databases. These tools will help speed up your process as you do not have to further search anywhere else for what you need.
Apache Graph
Apache Graph supports high-level scalability. It is an iterative graph processing system that has been specially developed for this purpose. This was derived from the Pregel model but comes with more number of features and functionalities when compared with the Pregel model. This open-source model helps data scientists to utilize the underlying potential of structured datasets at a large scale.
Some of its features include master computation functionality, out-of-core computation, and aggregators that are sharded, with edge-oriented input. It is inspired by the bulk synchronous parallel model, which supports distributed computation, introduced by Leslie Valiant. It has great community support, which also ensures that the development cycle is constantly growing. This will ensure that you get timely support as and when needed. Also, another interesting fact about this is that it has constant updates, so everything is new. This is available free of cost.
Apache HBase
This is another tool that is available free of cost. Apache HBase, also known as Hadoop database, is another scalable big data store. This distributed, open-source tool can be used whenever you need a random, real-time read or write access to big data. Apart from Hadoop and HDFS, with Apache HBase, you get capabilities similar to Bigtable.
Some of its features include scalability that is both linear and modular, it allows consistent read and writes. It offers automatic and configurable sharding of tables. This open-source tool is a distributed, versioned and non-relational database that is modeled after Google’s Bigtable, which is a distributed storage system for structured data.
Apache Spark

This is another free tool that offers cluster computing in a blink of the eye, which is at lightning bolt speed. Today, a number of organizations are using Spark for processing large datasets. This data scientist tool is capable of accessing diverse data sources, which include HDFS, HBase, S3, and Cassandra.
Some of its features include a number of high-level operators, which help in building parallel apps (the count is not known exactly – thought it would be more than 80), it can be used to interact with Scale, R shells and Python. It is capable of powering a huge stack of libraries, which include GraphX, Spark Streaming, MLlib, and DataFrames. This is an advanced DAG execution engine, which supports acyclic data flow and in-memory computing.
Apache Storm
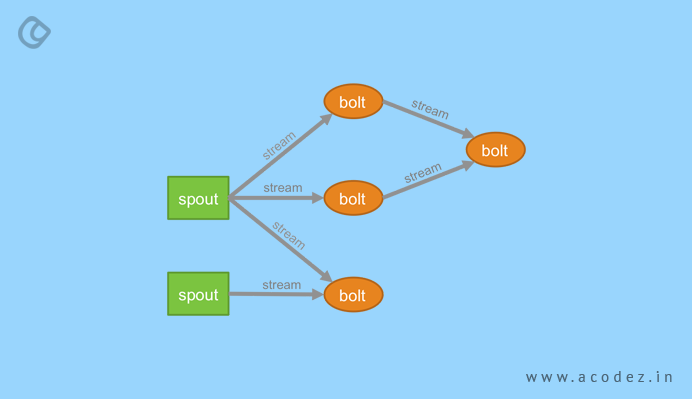
This is another interesting tool that helps data scientists to manage distributed along with fault-tolerant computation in real time. It also helps in managing computation constantly, distributed RPC, stream processing, etc. Some of its key features include being free and open-source. It helps in processing unbound data streams in real time. It can be integrated and used with any programming language of your choice.
It comes with use cases, including continuous computation, online machine learning, real-time analytics, distributed RPC, ETL software and others. It is capable of processing over one million tuples, per second, per mode. You can easily integrate it with your existing queueing and database technologies.
Cascading

This application development platform is specifically for data scientists who are building big data apps on Apache Hadoop. It allows users to solve both complex and simple data problems, using cascading. This is because it offers computation engines, data processing, scheduling capabilities, and systems integration framework.
Some of the key features include balancing the level of abstraction providing varying degrees of freedom, as required. It offers Hadoop development teams with a portability feature. By changing a few lines of code, you can port Cascading into another supported computer fabric. It can be executed and ported between MapReduce, Apache Flink, and Apache Tea. Also, it is available free of cost.
D3.js

Mike Bostock is the master brain behind D3.js. It was developed with an aim to code data for humans. It is mainly a JavaScript library, which helps in manipulating documents, which are based on data for adding life to their data using SVG, Canvas, and HTML.
Some of its key features include emphasizing web standards for gaining access to the entire set of capabilities of modern browsers without the need to have tied it to a proprietary framework. It combines highly powerful visualization components along with the data-driven approach for manipulating document object model (DOM). Then, it can bind arbitrary data to a DOM, which can be applied to bringing about data-driven transformation to any document. The best part of D3.js is that it is also available free of cost with all the above-specified features.
Excel

We are all well familiar with Excel. Most of us use it in our day-to-day lives. But in the life of a data scientist, Excel has far wider uses – it serves the purpose of a secret weapon. Scientists mainly use this tool as it helps to quickly sort, filter and manage the data that their working on. You can find it on every other computer that you come across. This means that it is easier for data scientists to work on data from anywhere at any time with ease.
Some of its features include offering named ranges, which help in creating a makeshift database. Another interesting feature is that it can be used for sorting and filtering with just one click and then exploring your dataset quickly. Based on criteria, you can specify a range which can be used as advanced filtering criteria to filter your dataset. It implements pivot tables to cross-tabulate data and also to calculate counts, sums and other metrics. Visual Basic offers a large variety of creative solutions. You can avail the first demo free of cost.
Cascading
We have already discussed cascading in a few of the previous instances. Here, we will take a deeper look at what exactly is Cascading and how does it make for an efficient tool. This is one of the best app development platforms for data scientists that are building big data apps on Apache Hadoop. It allows users to solve simple and complex data problems using Cascading as it comes with computation engines, data processing, systems integration framework, and scheduling capabilities.
Some of its interesting and key features include providing a balance for setting an ideal level of abstraction with the required levels of freedom. It also offers the Hadoop development teams the required level of portability, as discussed earlier. It allows you to make alterations to a few lines of code, while porting Cascading to another supported computer fabric, as per the requirements.
It can be executed and run or ported between Apache Tea, Apache Flink, and MapReduce. It is available for free.
Data RPM
One of the industry’s first and only cognitive predictive maintenance platform, which can be used for industrial internet of things (IoT). It has received the 2017 Technology Leadership Award for Cognitive Predictive Maintenance in Automotive Manufacturing from Frost and Sullivan.
Some of its key features include using patent-pending meta-learning technology, which is an integral component of artificial intelligence for automated prediction of asset failures. It helps in executing more than two live automated machine learning experiments across datasets. It helps in extracting data from each and every experiment, while training models on the metadata repository, which apply models for predicting the algorithms, which will perform the best while building machine-generated, human-verified machine learning models for predictive maintenance.
The workflow follows procedures, including feature engineering, influencing factors, segmentation along with prediction techniques that deliver the prescriptive suggestions as per requirements.
It might not be easy to become a data scientist. But while you are there, it is important that you have this above-mentioned list of data science tools for your needs handy.
Acodez Solutions is a web design and web development company in India offering all kinds of web design solutions at affordable prices. We are also a SEO agency offering inbound marketing solutions to help take your business to the next level. For further information, please contact us today.
Looking for a good team
for your next project?
Contact us and we'll give you a preliminary free consultation
on the web & mobile strategy that'd suit your needs best.